Summary
reMarkable is a Norwegian tech company behind the paper tablet, a device designed for thinking and focus without distractions. Since its inception, the company has revolutionized digital note-taking by providing a tactile, paper-like experience combined with powerful digital connectivity. To support their growing ecosystem of users and devices, reMarkable manages a sophisticated data infrastructure that handles high-volume processing and complex analytics.
The Challenge
reMarkable utilizes BigQuery and dbt for their extensive data transformation layer. The engineering team faced a persistent financial dilemma inherent to BigQuery’s pricing structures: workload heterogeneity. While some of their transformation queries were data-intensive and cheaper to run on a capacity-based reservation, others were compute-intensive with small data footprints, making them more economical on the on-demand model.
They required an automated way to treat queries individually and to run reservations efficiently in order to see any significant cost savings. The team also had limited experience managing complex capacity reservations and did not have the resources to dedicate to the constant manual monitoring and fine-tuning needed to prevent reservation waste and performance tradeoffs. Concluding there was nothing to gain (apart from the additional overhead of managing reservations), they decided to keep running everything on-demand.
The Solution
To resolve these trade-offs, reMarkable integrated Alvin’s autonomous agent into their dbt transformation pipelines. The implementation was designed to provide immediate ROI with minimal engineering overhead, effectively acting as an automated extension of their data team.
Alvin operates as a zero-latency high-performance proxy between reMarkable’s dbt environment and the BigQuery API, intercepting every query in real-time. The agent performs dynamic query routing by fingerprinting each job to analyze historical slot usage and bytes processed. Based on this analysis, Alvin determines the cost-optimal path - routing scan-heavy jobs to capacity reservations and keeping compute-heavy jobs on on-demand billing. To further eliminate financial and performance risk, Alvin utilizes its Autotamer feature to manage the reservation in real-time, providing only enough capacity to process the queries within Remarkable’s SLOs, minimizing waste and maximizing the differential to on-demand.
The Results
- 60% reduction in total BigQuery compute spend for dbt workloads.
- An industry-leading 1.2 Waste Factor, ensuring near-perfect alignment between billed capacity and actual utilization.
- Automated SLO compliance without manual engineering intervention.
- Guaranteed ROI through a performance-based pricing model.
“We were skeptical at the beginning and in hindsight, we should have just started using Alvin even earlier. The savings are substantial, but most importantly, how smooth and efficient the implementation process is. Very few vendors give you money back with no hidden clauses."
Martí Colominas, VP Head of Data & AI at reMarkable
Billing Model Optimization
Alvin continuously evaluates the computational profile of every query executed by reMarkable to calculate the most cost-effective execution path.
- For scan-heavy queries: Alvin leverages capacity reservations to bypass expensive per-byte charges.
- For compute-intensive queries: It retains on-demand billing, ensuring reMarkable only pays for data scanned rather than the high slot-seconds and large reservations required for complex processing.
As you can see from the chart below, the savings percentage is consistently high even as consumption varies:
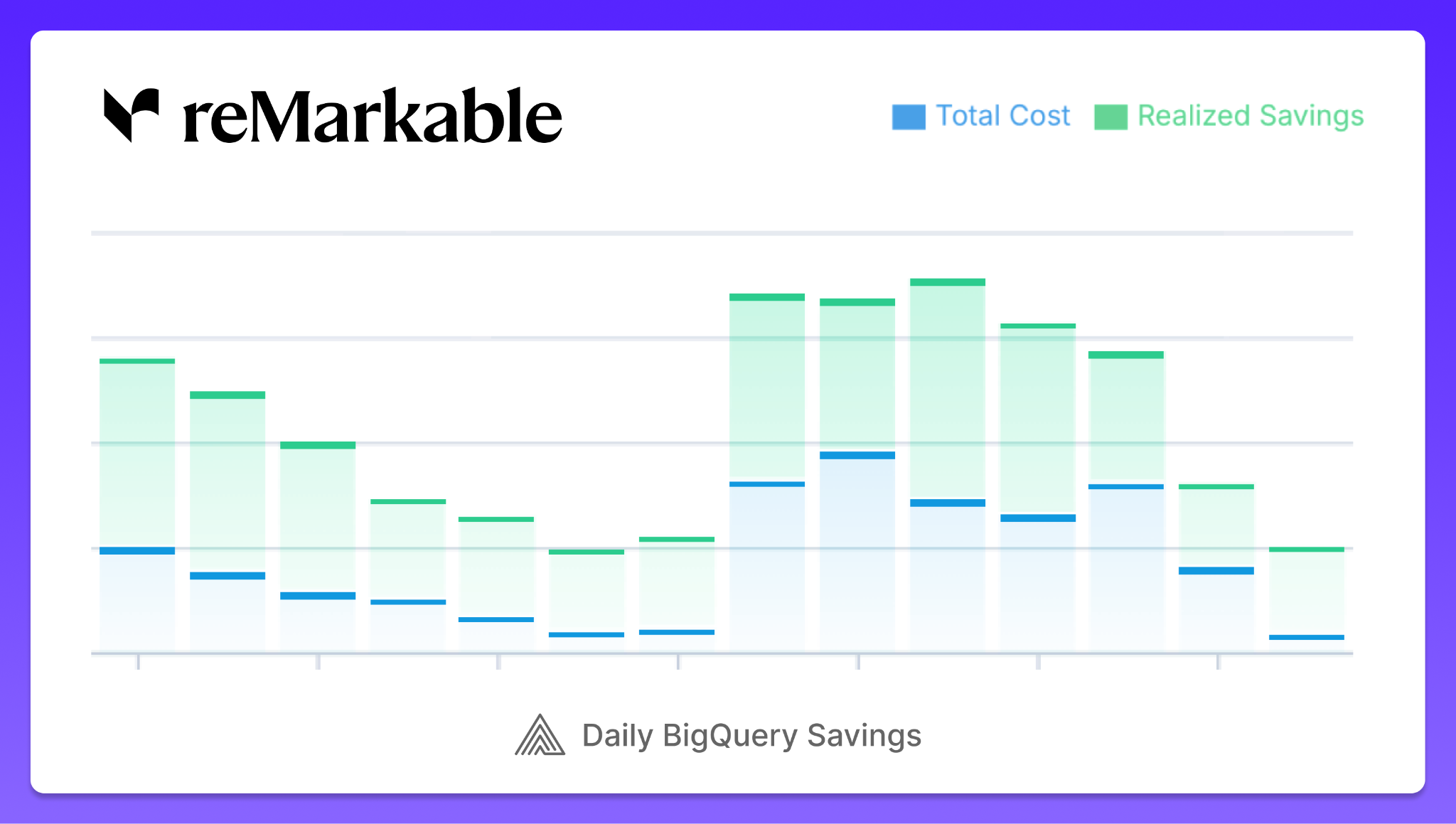
Automated Reservation Management
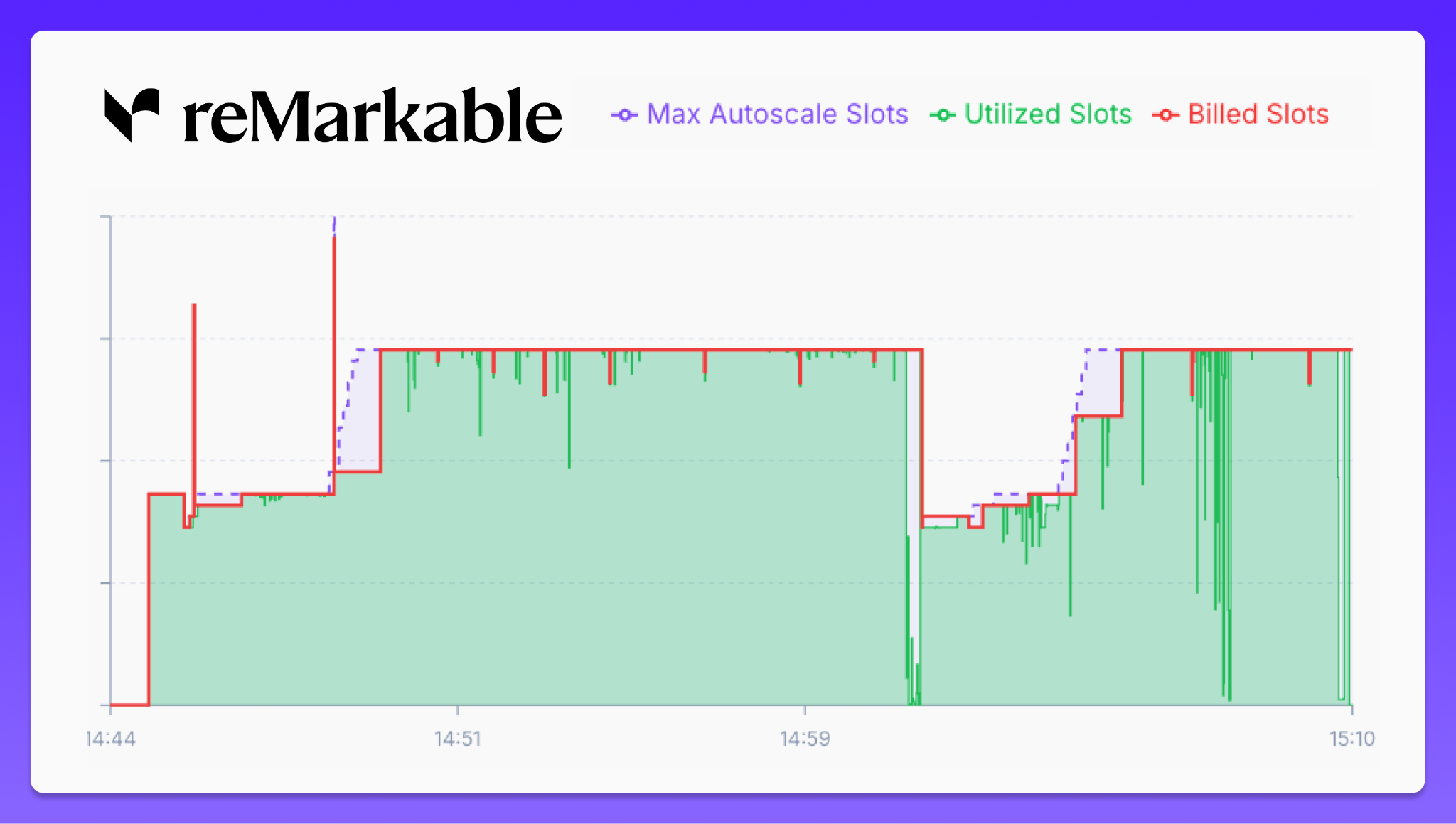
Beyond routing, Alvin manages reMarkable’s BigQuery reservations in real-time via API calls. This feature ensures that the theoretical savings of capacity billing are actually realized by eliminating "waste" (the cost of underutilized slots). By scaling resources at the second level, Alvin maintains reMarkable's performance standards while ensuring the highest effective saving rate. Because these are pipeline queries, rapid per-query performance was not the goal here–only that the dbt pipeline completed within their SLO to ensure the data was available for downstream use cases. The autotamer was therefore configured to aggressively cap the slots of the reservation to ensure close to full utilization, and scale up only when needed based on signals such as queuing and query duration.
You can see from the chart below how Alvin scales up capacity in real-time and back down again to meet their SLO whilst minimizing the slot waste:
Ready to Optimize Your Data Spend?
Discover how Alvin can transform your cloud data costs. Schedule a personalized demo or run a free savings analysis to quantify your potential outcomes and see immediate value.


